売上予測の具体的な手法とポイント
Release 2023/01/23

前回で売上予測のための商圏分析についてお伝えさせていただきました。今回はその発展形として売上予測の具体的な手法とポイントについて掘り下げたいと思います。
売上予測といってもその対象は様々なものがあります。日商や月商、または販促の効果予測など、多岐に渡ります。今回は私がこれまでお手伝いさせていただいたなかで、最も多かった『新規物件の売上予測を行うための、予測分析』について記載させていただきます。対象は月商とします(新規出店した際に、毎月どの程度の売上が見込めるか)。
目次
売上目標との違い
売上予測と似たような言葉として「売上目標」という言葉があります。売上予測、売上目標はどちらも未来の売上を指していることに変わりはありませんが、その意味は全く異なるため解説いたします。
「売上目標」はその名の通り「売上」の「目標」であるため、現状の実績や売上予測に基づいた「このくらい売りたい」という目標金額です。あくまで目指す指標であり、その数値には設定した人間の期待や想い(考え)が込められています。そのため、売上予測ほど精緻なデータに基づいている必要はありません。つまり何かのロジックや計算式によって算出されるのが売上予測であり、そこに個人や組織の考えが入るものが売上目標となります。
売上予測の前提
予測する対象は『新規物件の年間平均月商』とします。また今回の事例では、過去の実績をベースとして、既存店を分析対象とします。そのため、これまで出店したことのない新業態の予測の際には適さないことを注意してください。
売上予測に必要なデータ
次に必要なデータですが、以下のようなデータが必要となります。GISから取得できる統計データは必須と考えます。
今回の分析事例に活用したもの
- 店舗ごとの基礎情報データ(席数、営業時間、出店階)
- 各店舗の平均売上
- 店舗の住所(緯度経度)※GISを使用し統計データ取得
- 駅乗降客数データ
- 競合店住所(緯度経度)※GISを使用しプロットデータ集計
その他(あればより効果的なもの)
- 時間帯別売上
- お客様アンケート
- 顧客住所 ※GISを使用し商圏範囲分析(前号記載内容)
売上予測の分析手法
分析の方法ですが、売上予測には様々な手法があります。重回帰分析、決定木分析、ハフモデル分析、AI・機械学習を用いた分析(例:ランダムフォレスト)など、それぞれどのようなアウトプットを出したいか、何を分析するのか、によって選択する必要があります。今回はこれらの既存ツールではなく、エクセルを活用した“既存店との比較分析法”をご紹介いたします。
既存店比較分析とは、既存店の売上要因(売上に関係する項目)を点数化し、分析した既存店各店舗の点数と物件の点数を比較し、どの程度の売上が見込めるか試算する方法。
売上予測の具体的な手順
ではある架空の飲食企業を事例に売上予測の分析を実践してみます。企業の状況は以下のような状態とします。
- 事例:レストランチェーン店
- 店舗数:15店舗(全て駐車場のない1階出店店舗)
- 出店エリア:東京都
- 課題:新規出店における物件の売上予測が、社長やベテラン開発者の勘や経験のみ
- 要望:物件の売上予測ができる予測の仕組みがほしい(数値による判断)
- 店舗一覧
no. 店舗名 売上(千円) 1 新宿店 9,300 2 赤羽店 8,400 3 八王子店 8,200 4 渋谷店 8,000 5 立川店 7,500 6 吉祥寺店 7,200 7 浅草店 6,500 8 阿佐ヶ谷店 6,400 9 上野店 6,200 10 武蔵小金井店 6,000 11 高田馬場店 5,900 12 調布店 5,600 13 麻布十番店 5,500 14 武蔵小山店 5,500 15 原宿店 4,900 平均 6,740
分析企業は上記の定義とします。具体的な手順は以下のように考えております。
- クライアント(の運営店舗)を知る・経験する
- 売上要因について仮説構築
- 立てた仮説の検証
- 分析店舗での比較分析
- 分析店舗以外での検証
1. クライアント(の運営店舗)を知る・経験する
予測の仕組みを構築する際、皆様ならまずなにを実施するでしょうか。もちろん企業の状況によって必ずこれが正解、というものはないのですが、私の場合まず実施することは、クライアントの企業を知る(理解する)ことからスタートします。いきなり数値の分析や予測モデルを構築しようとしても、先方のレストランのことをなにも知らない状態では、決して精度や納得感の高い予測モデルはつくることができません(確度の高い仮説構築ができない≒精度の高いモデルがつくれない)。そのため、なによりも先に先方の店舗がどのような飲食店で、どのようなお客様が来店されているのか、を自身で知り、且つ利用できる業態なら、自分がお客様になって体験することが最も重要であると考えます(先方と同じ土俵に立つことが何よりも大切だと思います)。※このクライアント企業を知るという行為の際に、先に述べた「時間帯別売上」や「お客様アンケート」が重要になってきます。
2. 売上要因について仮説構築
ある程度分析対象である業態の特徴を掴めたあとは、実際の分析に向けた準備を行います(自身の在籍している店舗である場合は、ここからスタートかもしれません)。それが『売上要因についての仮説構築』です。
つまり、売上の高い店舗に共通していることはなんなのか、売上の低い店舗に共通していることはなんなのかを、箇条書きでもなんでも構わないので、書き出していきます。この時の注意点としては、間違っていてもよいので、より多くの仮説を出すことです(接客が良い、などの要素でも構いません)。また、その仮説を出すのに考えた具体的な店舗や、仮説の理由があるとなお良いです。例えば、以下のようなものです。
- 席数の多さは高売上に繋がる(●●店、ピークタイムの売り逃しが少ない)
- 昼に人が集まるような町がプラス
- 最寄り駅の乗降客数が多いほうが良い
- 最寄り駅に近いほうが良い
ここの仮説の多さと確度の高さが、次の分析がスムーズにすすむかどうかの鍵となります。さらにこの仮説を出すためには、店舗のことを良く知っておく必要があるので、「店舗を知る・理解する」ことが非常に重要、ということに繋がってきます。
3. 立てた仮説の検証
仮説は立てただけでは十分とはいえず、その検証を実施して本当に分析に使用してよいかどうかを判断していきます。例えば1つ目の席数の多さですが、席数が多い=売上が高いことはなんとなく良さそうですが、数値によって証明していきます。その際、最も簡単な方法としては、2つのデータの相関関係を見ることです。売上の高低と席数の高低が相関していれば、その2つのデータは関係性が高いと判断して良いと考えます(相関:一方が変化すれば他方も変化するように相互に関係しあうこと/エクセル関数のCORRELで算出することができます)。こうして立てた仮説を表現できる項目と売上との相関を確認し、自身の仮説が正しそうかどうか(100%正しいとは言い切れません)を確認していきます。
相関関係の確認
| no. | 店舗名 | 売上(千円) | 席数 | 0.5km昼間人口総数 | 0.5km昼夜間人口比率 | 最寄り駅乗降客数 | 最寄り駅までの距離 |
|---|---|---|---|---|---|---|---|
| 1 | 新宿店 | 9,300 | 33 | 112,564 | 3465% | 1,550,772 | 100 |
| 2 | 赤羽店 | 8,400 | 19 | 22,805 | 142% | 196,740 | 10 |
| 3 | 八王子店 | 8,200 | 30 | 28,689 | 298% | 167,130 | 50 |
| 4 | 渋谷店 | 8,000 | 11 | 85,841 | 1591% | 732,256 | 100 |
| 5 | 立川店 | 7,500 | 18 | 40,781 | 441% | 333,272 | 30 |
| 6 | 吉祥寺店 | 7,200 | 20 | 31,810 | 332% | 283,698 | 21 |
| 7 | 浅草店 | 6,500 | 25 | 24,683 | 161% | 108,434 | 150 |
| 8 | 阿佐ヶ谷店 | 6,400 | 22 | 15,043 | 89% | 91,206 | 100 |
| 9 | 上野店 | 6,200 | 10 | 53,385 | 620% | 365,408 | 100 |
| 10 | 武蔵小金井店 | 6,000 | 12 | 10,743 | 83% | 125,130 | 20 |
| 11 | 高田馬場店 | 5,900 | 21 | 44,337 | 277% | 416,048 | 110 |
| 12 | 調布店 | 5,600 | 20 | 21,047 | 176% | 345,375 | 200 |
| 13 | 麻布十番店 | 5,500 | 15 | 21,083 | 129% | 49,271 | 96 |
| 14 | 武蔵小山店 | 5,500 | 23 | 14,206 | 71% | 53,193 | 78 |
| 15 | 原宿店 | 4,900 | 21 | 37,316 | 714% | 163,780 | 150 |
| 売上(千円)との相関関係 | 0.37 | 0.59 | 0.60 | 0.63 | -0.45 | ||
※ 0.5km昼夜間人口比率…0.5km昼間人口÷0.5km住基人口によって算出
立てた仮説に対しては、席数、昼間人口(昼の人口)や昼夜間人口比率、駅乗降客数はプラスになっているので、正の相関があり、駅までの距離は負の相関となっています。駅までの距離は、近いほど売上が高くなるという仮説だったため、負の相関ということは、仮説に近いということとなるため、これらの4項目は仮説に合っているといえそうです。
※ 分析店舗が少ない場合、1店舗サンプルが増える(減る)だけで、相関関係は大きく動きます。そのため、特定の1店舗によって相関関係が歪まされていないか、などは注意が必要です。
また、相関だけでも仮説の検証は十分とはいえないため、各仮説に対する検証は多角的に実施することが大切です(例えば、昼の需要が重要ならば、時間帯別売上でピーク時間を確認することや、実際に昼に店舗に来店し、来客状況を確認するなど)。
4. 分析店舗での比較分析
ここまでで、仮説とその仮説に対する検証がある程度できたものとします。次にいよいよ比較分析を行います。これまで仮説立て、数値検証を実施したデータを使用し、分析店舗を表現します。その際、15店舗全てを分析に使用することはおススメしません。なぜなら、検証ができなくなってしまうからです。今回の場合ならば、10店舗で分析を行い、その分析結果を残りの5店舗に当てはめ(新規物件と見立てる)、精度の検証することが良いと思います。まずは分析店舗と使用するデータを抽出します。高売上店舗、低売上店舗、平均的な店舗からランダムに10店舗を抽出しました。
分析店舗と使用データ
| 店舗名 | 新宿店 | 八王子店 | 立川店 | 浅草店 | 阿佐ヶ谷店 | 上野店 | 武蔵小金井店 | 高田馬場店 | 調布店 | 原宿店 | 平均 | 係数 平均÷2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 平均売上 | 9,300 | 8,200 | 7,500 | 6,500 | 6,400 | 6,200 | 6,000 | 5,900 | 5,600 | 4,900 | 6,650 | 2,660 |
| 席数 | 33 | 30 | 18 | 25 | 22 | 10 | 12 | 21 | 20 | 21 | 21 | 8 |
| 営業時間(1週間) | 77.0 | 84.0 | 72.0 | 80.5 | 84.0 | 70.0 | 84.0 | 77.0 | 77.0 | 70.0 | 78 | 31 |
| 施設店舗面積 | 0 | 29,000 | 24,777 | 11,350 | 7,857 | 21,759 | 1,400 | 0 | 18,000 | 0 | 11,414 | 4,566 |
| 0.5km昼間人口総数 | 112,564 | 28,689 | 40,781 | 24,683 | 15,043 | 53,385 | 10,743 | 44,337 | 21,047 | 37,316 | 38,859 | 15,544 |
| 0.5km小売事業所数 | 1,144 | 427 | 572 | 655 | 285 | 676 | 128 | 190 | 237 | 703 | 502 | 201 |
| 0.5km昼夜間人口比率 | 3464.6% | 298.5% | 440.7% | 161.1% | 89.5% | 619.7% | 83.0% | 277.2% | 176.0% | 714.2% | 632.4% | 253% |
| 1km住基人口総数 | 28,019 | 40,006 | 37,473 | 71,600 | 68,607 | 41,140 | 44,676 | 61,008 | 47,443 | 20,677 | 46,065 | 18,426 |
| 最寄り駅乗降客数 | 1,550,772 | 167,130 | 333,272 | 108,434 | 91,206 | 365,408 | 125,130 | 416,048 | 345,375 | 163,780 | 366,656 | 146,662 |
| 最寄り駅までの距離 | 100 | 50 | 30 | 150 | 100 | 100 | 20 | 110 | 200 | 150 | 101 | 40 |
| 最寄り既存店までの距離 | 310 | 8,157 | 108 | 1,469 | 5,113 | 763 | 6,307 | 1,967 | 6,297 | 759 | 3,125 | 1,250 |
| 0.5km競合店舗数 | 37 | 9 | 12 | 10 | 3 | 13 | 4 | 7 | 7 | 6 | 11 | 4 |
このままでは、各項目の単位が異なるため、なにがどの程度良いのかわかりません。そこで、一定のルールに基づき、各項目を点数化します。私はいつも分析店舗の平均が2.5点になるようにし、点数は0~5点の間で動くようにします。
※ 平均÷2.5で係数を作り、その数値で各店舗の数値を割り戻すやり方をしています。
分析店舗の項目点数化
| 店舗名 | 新宿店 | 八王子店 | 立川店 | 浅草店 | 阿佐ヶ谷店 | 上野店 | 武蔵小金井店 | 高田馬場店 | 調布店 | 原宿店 |
|---|---|---|---|---|---|---|---|---|---|---|
| 平均売上 | 9,300 | 8,200 | 7,500 | 6,500 | 6,400 | 6,200 | 6,000 | 5,900 | 5,600 | 4,900 |
| 席数 | 3.9 | 3.5 | 2.1 | 2.9 | 2.6 | 1.2 | 1.4 | 2.5 | 2.4 | 2.5 |
| 営業時間(1週間) | 2.5 | 2.7 | 2.3 | 2.6 | 2.7 | 2.3 | 2.7 | 2.5 | 2.5 | 2.3 |
| 施設店舗面積 | 0.0 | 5.0 | 5.0 | 2.5 | 1.7 | 4.8 | 0.3 | 0.0 | 3.9 | 0.0 |
| 0.5km昼間人口総数 | 5.0 | 1.8 | 2.6 | 1.6 | 1.0 | 3.4 | 0.7 | 2.9 | 1.4 | 2.4 |
| 0.5km小売事業所数 | 5.0 | 2.1 | 2.9 | 3.3 | 1.4 | 3.4 | 0.6 | 0.9 | 1.2 | 3.5 |
| 0.5km昼夜間人口比率 | 5.0 | 1.2 | 1.7 | 0.6 | 0.4 | 2.4 | 0.3 | 1.1 | 0.7 | 2.8 |
| 1km住基人口総数 | 1.5 | 2.2 | 2.0 | 3.9 | 3.7 | 2.2 | 2.4 | 3.3 | 2.6 | 1.1 |
| 最寄り駅乗降客数 | 5.0 | 1.1 | 2.3 | 0.7 | 0.6 | 2.5 | 0.9 | 2.8 | 2.4 | 1.1 |
| 最寄り駅までの距離 | 2.5 | 3.8 | 4.3 | 1.3 | 2.5 | 2.5 | 4.5 | 2.3 | 0.0 | 1.3 |
| 最寄り既存店までの距離 | 0.2 | 5.0 | 0.1 | 1.2 | 4.1 | 0.6 | 5.0 | 1.6 | 5.0 | 0.6 |
| 0.5km競合店舗数 | 0.0 | 2.9 | 2.2 | 2.7 | 4.3 | 2.0 | 4.1 | 3.4 | 3.4 | 3.6 |
| 合計 | 30.7 | 31.4 | 27.5 | 23.3 | 25.0 | 27.3 | 22.9 | 23.2 | 25.4 | 21.2 |
ここまでで、合計点数と売上の相関は0.88あるので、このままでもある程度の精度はあるのですが、ここに各項目へウエイトを付与します(重回帰分析の場合はここに自動でウエイトが振り分けられますが、今回の方法では仮説ベースで付与します。その仮説ベースのウエイトが正しいかどうかは、検証によって明らかにします)。
ウエイトの付与
| ウエイト | 店舗名 | 新宿店 | 八王子店 | 立川店 | 浅草店 | 阿佐ヶ谷店 | 上野店 | 武蔵小金井店 | 高田馬場店 | 調布店 | 原宿店 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| - | 平均売上 | 9,300 | 8,200 | 7,500 | 6,500 | 6,400 | 6,200 | 6,000 | 5,900 | 5,600 | 4,900 |
| 2.0 | 席数 | 7.8 | 7.1 | 4.2 | 5.9 | 5.2 | 2.4 | 2.8 | 5.0 | 4.7 | 5.0 |
| 1.0 | 営業時間(1週間) | 2.5 | 2.7 | 2.3 | 2.6 | 2.7 | 2.3 | 2.7 | 2.5 | 2.5 | 2.3 |
| 1.0 | 施設店舗面積 | 0.0 | 5.0 | 5.0 | 2.5 | 1.7 | 4.8 | 0.3 | 0.0 | 3.9 | 0.0 |
| 2.0 | 0.5km昼間人口総数 | 10.0 | 3.7 | 5.2 | 3.2 | 1.9 | 6.9 | 1.4 | 5.7 | 2.7 | 4.8 |
| 1.5 | 0.5km小売事業所数 | 7.5 | 3.2 | 4.3 | 4.9 | 2.1 | 5.1 | 1.0 | 1.4 | 1.8 | 5.3 |
| 1.0 | 0.5km昼夜間人口比率 | 5.0 | 1.2 | 1.7 | 0.6 | 0.4 | 2.4 | 0.3 | 1.1 | 0.7 | 2.8 |
| 2.0 | 1km住基人口総数 | 3.0 | 4.3 | 4.1 | 7.8 | 7.4 | 4.5 | 4.8 | 6.6 | 5.1 | 2.2 |
| 1.0 | 最寄り駅乗降客数 | 5.0 | 1.1 | 2.3 | 0.7 | 0.6 | 2.5 | 0.9 | 2.8 | 2.4 | 1.1 |
| 2.0 | 最寄り駅までの距離 | 5.0 | 7.5 | 8.5 | 2.6 | 5.0 | 5.0 | 9.0 | 4.6 | 0.1 | 2.6 |
| 1.0 | 最寄り既存店までの距離 | 0.2 | 5.0 | 0.1 | 1.2 | 4.1 | 0.6 | 5.0 | 1.6 | 5.0 | 0.6 |
| 1.0 | 0.5km競合店舗数 | 0.0 | 2.9 | 2.2 | 2.7 | 4.3 | 2.0 | 4.1 | 3.4 | 3.4 | 3.6 |
| 合計 | 46.1 | 43.8 | 40.0 | 34.6 | 35.6 | 38.4 | 32.3 | 34.6 | 32.3 | 30.2 | |
| 理論値 | 8,914 | 8,346 | 7,429 | 6,126 | 6,350 | 7,032 | 5,559 | 6,124 | 5,560 | 5,060 | |
| 誤差 | 386 | -146 | 71 | 374 | 50 | -832 | 441 | -224 | 40 | -160 | |
| 4.3% | -1.8% | 1.0% | 6.1% | 0.8% | -11.8% | 7.9% | -3.7% | 0.7% | -3.2% | ||
付与したウエイト分、各項目の点数が変化しているのがわかると思います。ウエイトをかける際は、合計点数と売上で1次方程式(y=ax+b)を作り、理論値を算出します。その理論値と実績(平均売上)の誤差を算出し、その誤差と各項目の相関を算出することで、ある程度どの項目にウエイトをかければ、誤差が縮まるかは数値で判断することができます(今回はそのような手法があるとご理解いただければ十分です)。
実績値と理論値の散布図
分析した店舗の散布図を見てみます。実績値と理論値の相関関係は0.958となり、非常に相関関係は高いといえます。
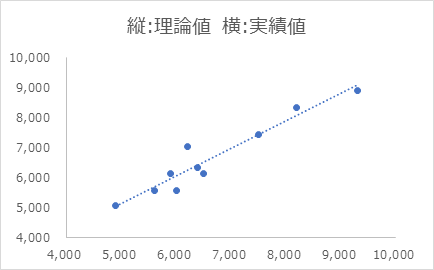
5. 分析店舗以外での検証
ここまでで、ある程度のモデルは構築できました。但し、サンプルのなかだけでの精度では実際に運用したときにどの程度の誤差が発生するのかはわかりません。そこで、サンプル以外の店舗を物件と見立てて、検証を行います(同じロジックで点数化し、同じウエイトを与え、理論値を算出)。すると、以下のような結果が得られました。
検証店舗結果
| 店舗名 | 赤羽店 | 渋谷店 | 吉祥寺店 | 麻布十番店 | 武蔵小山店 |
|---|---|---|---|---|---|
| 平均売上 | 8,400 | 8,000 | 7,200 | 5,500 | 5,500 |
| 席数 | 4.5 | 2.6 | 4.7 | 3.5 | 5.4 |
| 営業時間(1週間) | 2.5 | 2.5 | 2.5 | 2.7 | 2.5 |
| 施設店舗面積 | 1.3 | 2.2 | 2.7 | 0.0 | 0.0 |
| 0.5km昼間人口総数 | 2.9 | 10.0 | 4.1 | 2.7 | 1.8 |
| 0.5km小売事業所数 | 2.3 | 7.4 | 7.0 | 1.7 | 1.9 |
| 0.5km昼夜間人口比率 | 0.6 | 5.0 | 1.3 | 0.5 | 0.3 |
| 1km住基人口総数 | 6.4 | 2.7 | 4.3 | 5.4 | 8.7 |
| 最寄り駅乗降客数 | 1.3 | 5.0 | 1.9 | 0.3 | 0.4 |
| 最寄り駅までの距離 | 9.5 | 5.0 | 9.0 | 5.3 | 6.2 |
| 最寄り既存店までの距離 | 4.5 | 0.1 | 0.1 | 2.4 | 2.8 |
| 0.5km競合店舗数 | 3.6 | 0.0 | 2.0 | 4.3 | 3.8 |
| 合計 | 39.3 | 42.6 | 39.7 | 28.9 | 33.8 |
| 理論値 | 7,272 | 8,052 | 7,354 | 4,731 | 5,924 |
| 誤差 | 1,128 | -52 | -154 | 769 | -424 |
| 15.5% | -0.6% | -2.1% | 16.3% | -7.2% |
全体的に精度は良さそうですが、赤羽店に1,000千円以上の誤差が発生しています。この後は赤羽店に対して、なぜ誤差が発生しているのか、データは正しいのか、誤差に対する仮説はなにか、モデルで評価できていない項目はないかなどを再分析し、より精度の高いモデルを目指します。
予測精度を高めるポイント
いくら数値を使って分析を実施しても、精度が低ければ使い物になりません。より精度を高めていく必要があるのですが、精度を高めるためにはいくつかポイントがあります。
- 数字ベースではなく、仮説ベースで組み立てる
- 仮説⇔検証を繰り返す
- 誤差を0にすることをゴールにしない
相関が高い≒売上要因ではありません。立てた仮説の検証として数字を使いましょう。でなければ、誤った予測式を構築してしまい、結果として精度は上がりません(さらに他の人にも説明ができなくなります≒分析結果の納得感がない⇒だれも使わない)。
ある程度確度の高い仮説を構築できたら、その検証を行います。結果よければ、その仮説を採用し、ダメだったなら別の仮説を構築します。この仮説⇔検証のサイクルを高速で回すことができれば、より精度の高いモデルに近づくことができると思います。
誤差が少ないことは理論上の精度が高いモデルといえます。しかし誤差を完璧に埋めることが正しいというわけではないということは覚えておく必要があります。統計や数値分析は完璧ではなく、当たり前ですが、表現できない(あえてしていない)要素もあります。たとえば人の要素です。「あの店舗は能力の高い店長がいるから売上が高い」という仮説の店舗があり、さらにその検証として、その店長着任後の売上を確認すると、昨年よりも10%売上が伸びていました(仮説の検証)。その店舗をモデルで表現する場合は、人の要素を要因に入れていないとすると、誤差が10%発生することが正しいということになります。
このように分析モデルでなにを表現し、何を表現していないかを明確化し、解消すべき誤差を正しく認識することも分析者として重要です。
最後に
今回は実際に企業が行っている予測分析についてご紹介いたしました。あくまで1つの方法であり、その他にも方法はいくつも存在します。但し、前述した「精度を高めるポイント」については、どの手法を選択したとしても、必要になる考え方だと思います。また前号で紹介した商圏分析、今回の分析に使用した統計データなど、このような分析を実施するためにはGISが必要不可欠な要素であると考えています。前回や今回の内容が記事を読んでいただいた皆様の一助になれば幸いです。
